Full 3D estimation of human pose from a single image remains a challenging task
despite many recent advances. In this paper, we explore the hypothesis that
strong prior information about scene geometry can be used to improve pose
estimation accuracy. To tackle this question empirically, we have assembled a
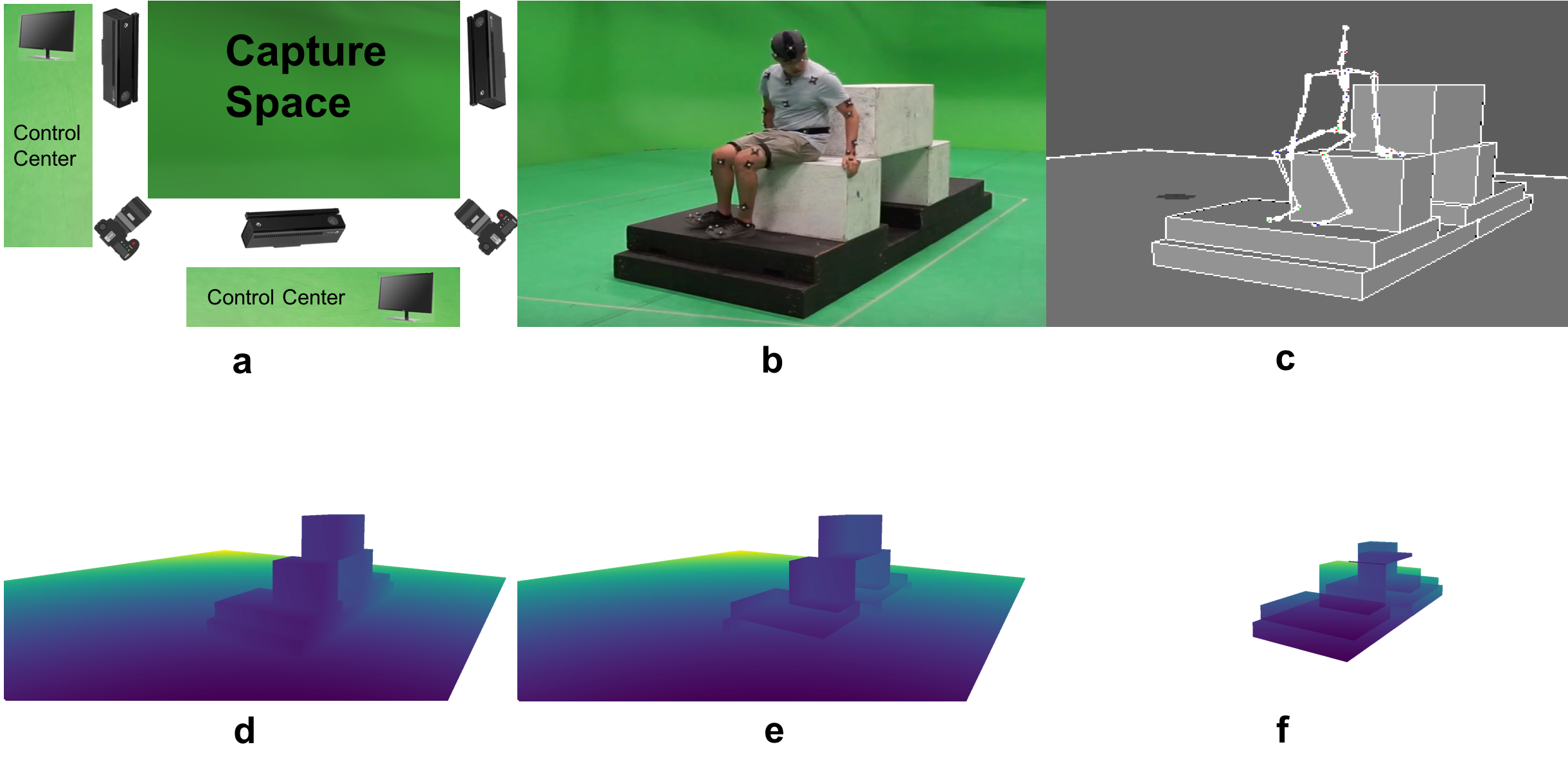
novel (
Geometric Pose Affordance) dataset, consisting of multi-view
imagery of people interacting with a variety of rich 3D environments. We
utilized a commercial motion capture system to collect gold-standard estimates
of pose and construct accurate geometric 3D CAD models of the scene itself.
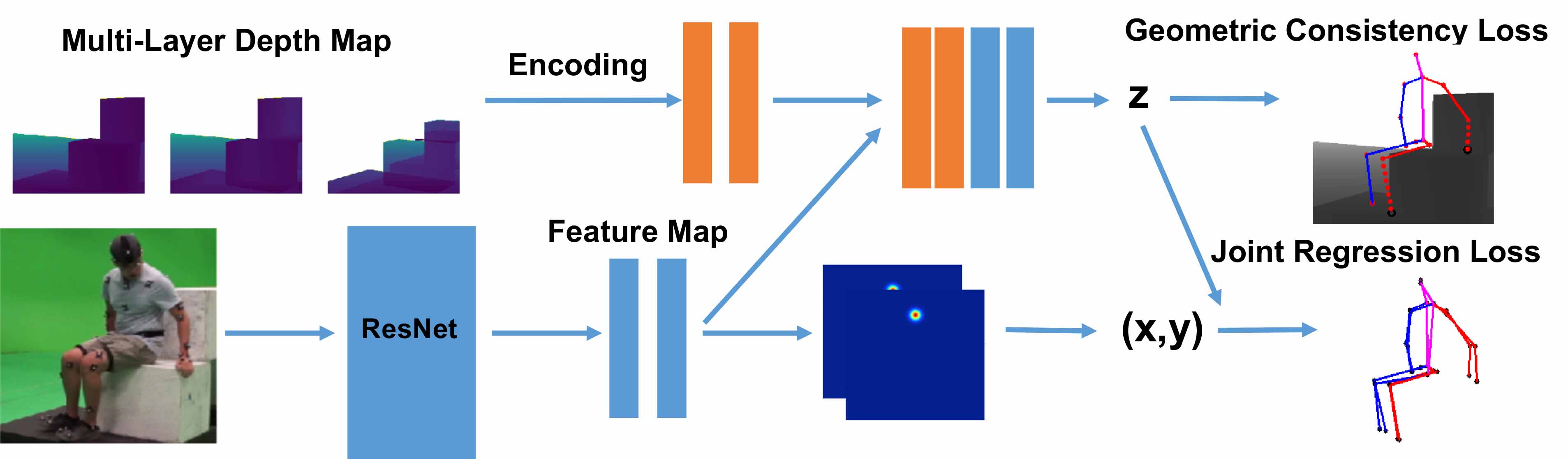
To inject prior knowledge of scene constraints into existing frameworks for
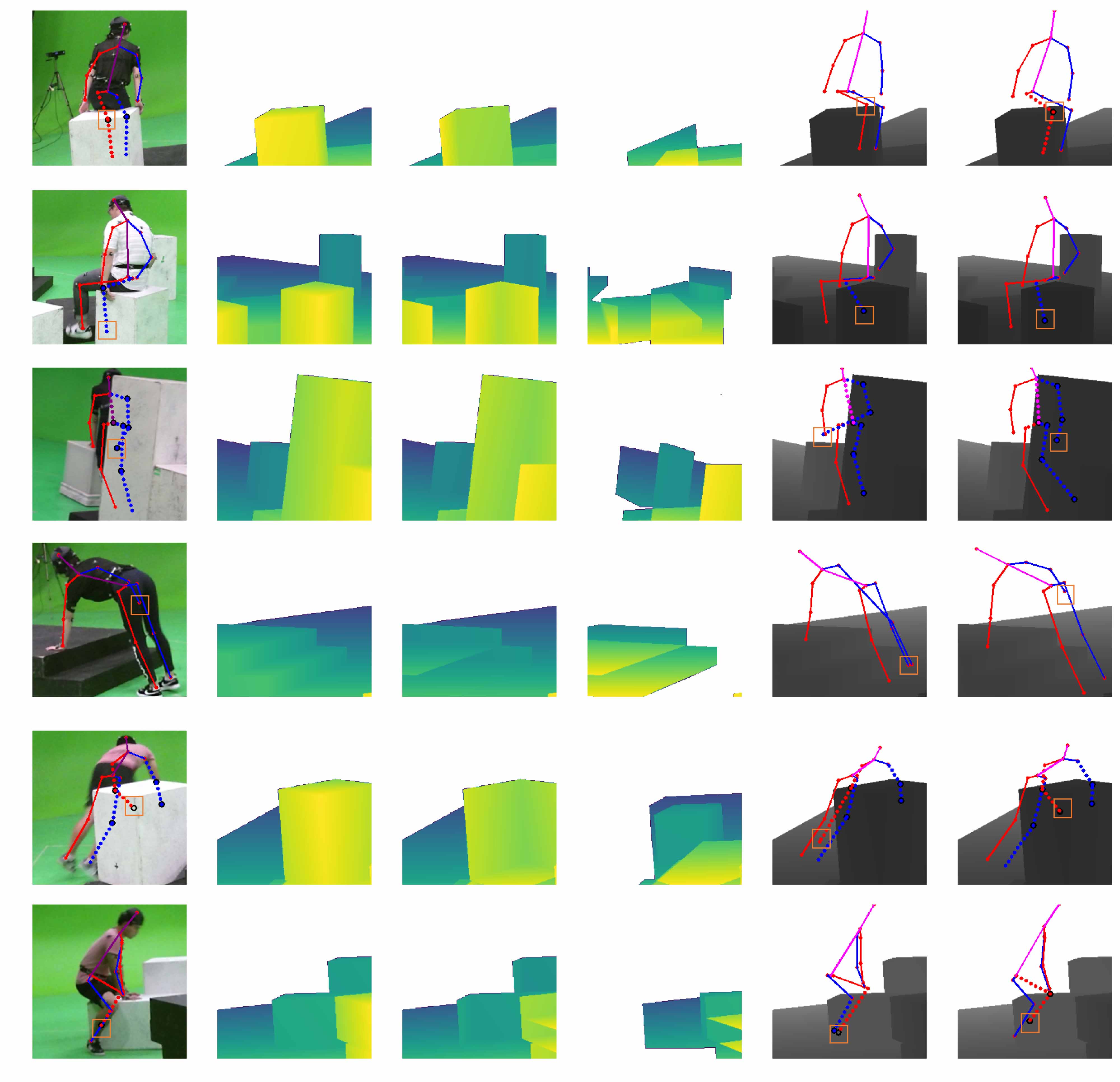
pose estimation from images, we introduce a novel, view-based representation of
scene geometry, a (
multi-layer depth map), which employs multi-hit ray
tracing to concisely encode multiple surface entry and exit points along each
camera view ray direction. We propose two different mechanisms for
integrating multi-layer depth information pose estimation:
input as encoded ray features used in lifting 2D pose to full 3D, and secondly
as a differentiable loss that encourages learned models to favor geometrically
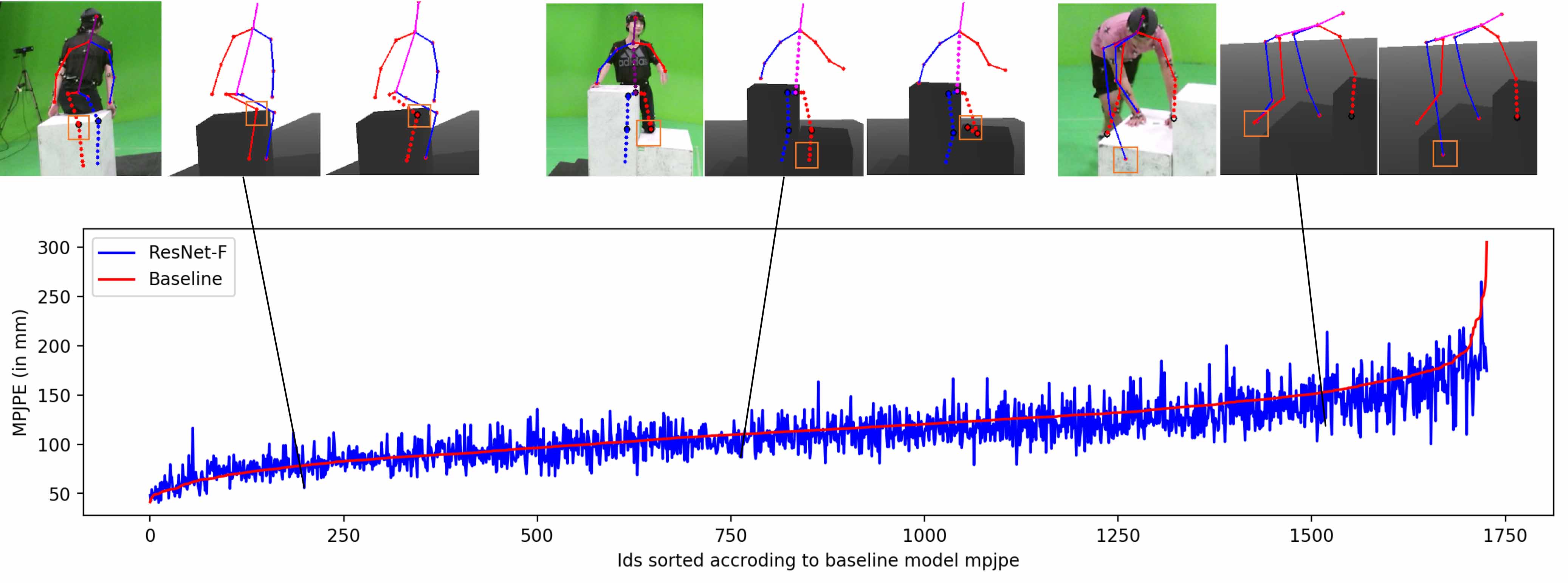
consistent pose estimates. We show experimentally that these techniques can
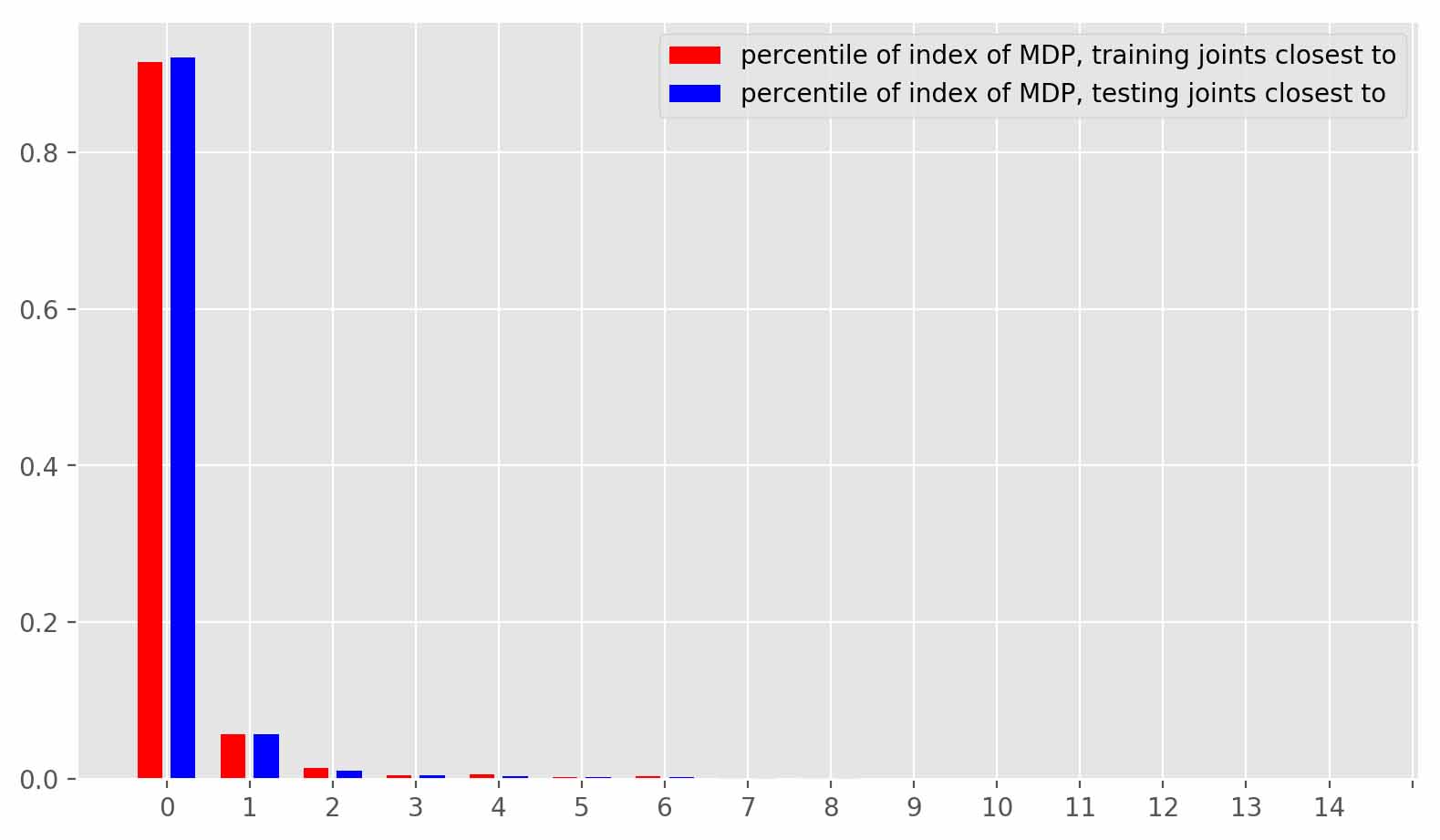
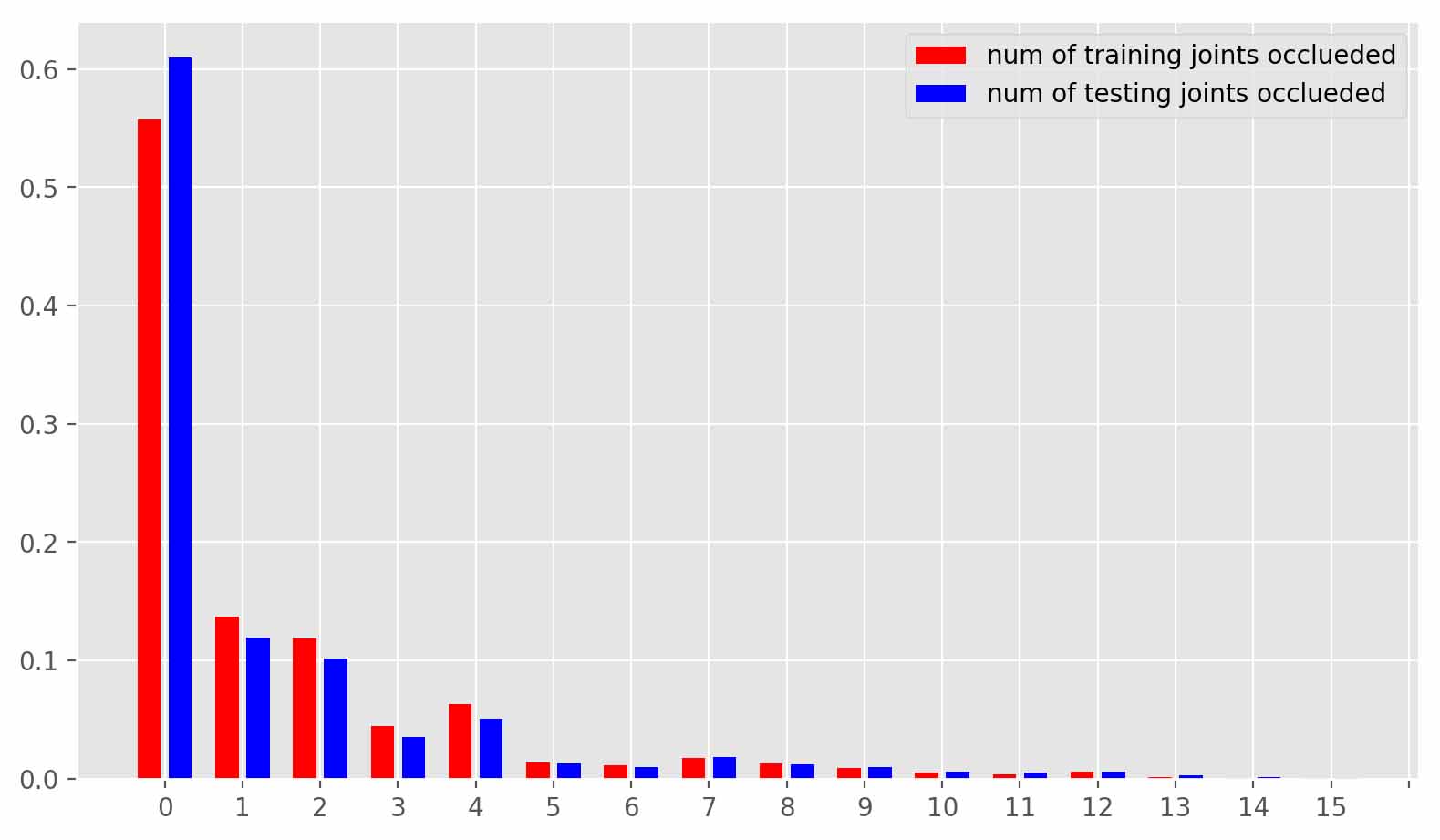
improve the accuracy of 3D pose estimates, particularly in the
presence of occlusion and complex scene geometry.
Low Resolution PDF